北大团队发布首个复数量化模型iFairy
2025-08-17 09:16为破解大模型部署与推理成本高昂的困境,近日,北京大学杨仝教授团队首次提出名为iFairy的超低比特量化方案。该方案创新性地利用复数{±1, ±i}对模型权重进行2-bit量化,在实现1/8极致压缩与“无乘法”推理加速的同时,语言建模能力和下游任务表现反超了同尺寸的全精度LLaMA基座模型。相关论文题为“iFairy: the First 2-bit Complex LLM with All Parameters in {±1, ±i}”。
研究聚焦于大语言模型在真实应用中的空间和时间瓶颈。传统全精度模型参数量大、推理能耗高;尽管已有低比特量化降低了模型体积,但核心矩阵乘法仍广泛依赖乘法运算,难以从根本上压缩推理时延和能耗。为此,团队提出在复数平面进行2-bit量化:通过相位映射将权重限定为四个单位根{+1, −1, +i, −i},在不增加位宽的情况下充分利用2 bit信息容量,同时保持量化集合的对称性和训练稳定性。
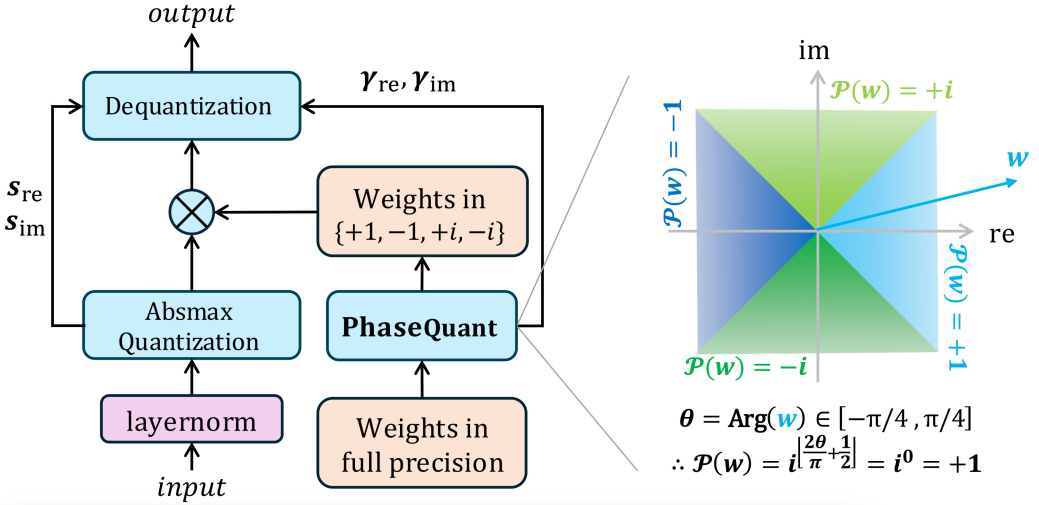
PhaseQuant量化算法示意图
在实现层面,iFairy配套提出PhaseQuant量化策略与复数化Transformer设计。当量化权重取{±1, ±i}时,张量乘法可退化为符号翻转、实虚部交换与加减等低成本操作,从而在核心GEMM中大幅减少乘法指令;同时在注意力计算中使用Hermitian内积的实部得到实值相似度分数,并在位置编码中采用复数旋转形式,实现与主流Transformer架构的兼容。得益于2-bit权重表示,模型存储相较FP16可压缩至约1/8,具备向边缘端落地的潜在优势。
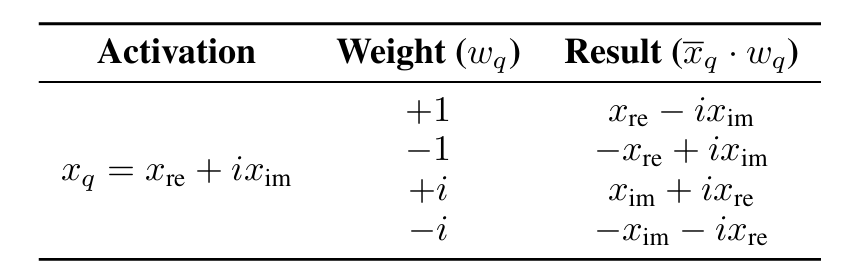
超低比特复数运算规则
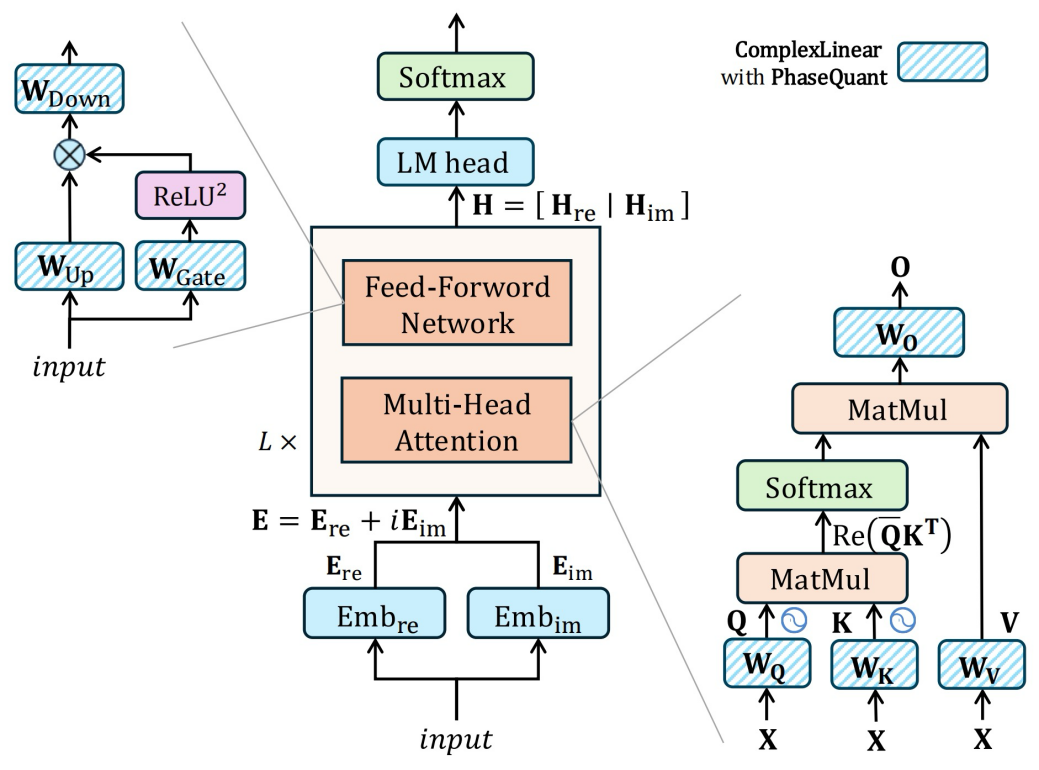
iFairy模型主干
在与同规模全精度(FP16/BF16)基座模型对齐的数据与训练条件下,团队报告的结果显示:在语言建模任务上,2-bit iFairy的困惑度(PPL)较全精度模型有明显下降,部分数据集上的降幅约可达10%;在若干zero-shot下游任务评测中,1.3B规模的2-bit模型平均分略高于全精度基座,700M规模随任务有所差异但整体保持竞争力。进一步的参数分布分析显示,训练后量化权重在{±1, ±i}之间分布较为均衡,表明模型能够有效利用复数码本进行表示学习。
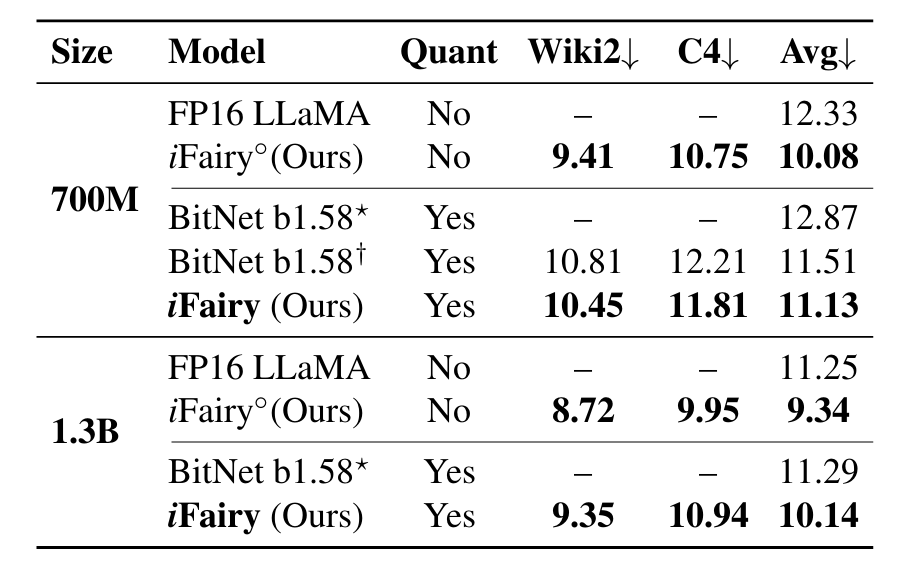
iFairy PPL评测结果
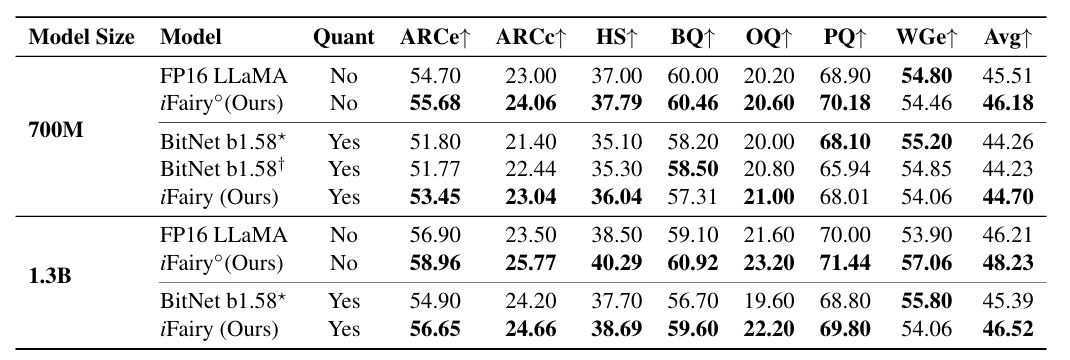
iFairy下游任务评测结果(zero-shot)
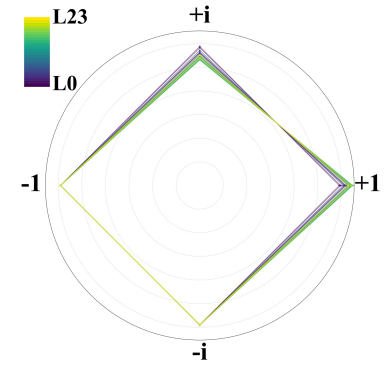
iFairy模型k_proj的参数分布
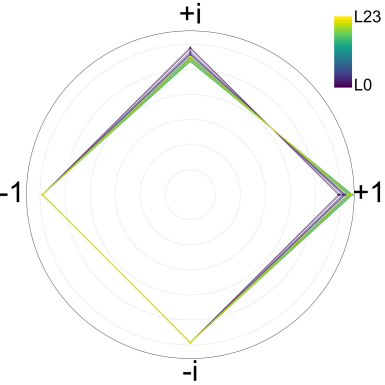
iFairy模型o_proj的参数分布
该研究在“高效表示—无乘法推理—复数化结构”三方面提出系统性方案,为在有限资源条件下实现高性能推理提供了新的技术路径,也为今后在移动终端与其他资源受限场景中的大模型部署带来新的可能。
杨仝团队希望在未来围绕复数域算法与硬件协同设计、端侧部署优化以及更大规模预训练验证等方向持续推进研究,推动高效大模型技术走向产业化与开放共享。相关论文、训练代码、模型权重与实验脚本已全部开源,配套提供从训练、评测到可复现实验的完整流程,人人皆可复现训练。

杨仝及其团队(从左至右:黄博楷,张艺豪,杨仝,王国安,陈齐治)
信息来源:北京大学计算机学院

